卡尔曼滤波
文章目录
引言
最近项目需要,要做目标跟踪以及轨迹预测的算法,翻了翻论文,应用比较多的就是卡尔曼滤波了。以前本科的时候就听过卡尔曼滤波,学大地测量的做卫星轨道预测时好像经常会用到这个,不过那时本身用不到,也就没关注。现在需要用到了,就去学习了一下,这里算是将其总结记录一下吧。
Kalman filter 的提出到现在已经快60年了,但其应用仍然十分广泛,只要是对动态系统不确定的状态估计,基本都可以看到kalman滤波的身影。
状态预测
已知物体某一时刻的状态(例如:位置,速度,运动方向等),如何对其下一时刻的位置进行预测?卡尔曼滤波便是用来解决这一类问题而提出的。假设一个物体的状态向量表示如下:
\[ \boldsymbol{x} = \begin{bmatrix} p \\ v \end{bmatrix} \]
卡尔曼滤波假设状态向量中的变量均符合高斯分布,具有均值$\mu$ ,以及方差 $\sigma^2$ 。 状态向量的协方差矩阵为 $\mathbf{P}$ ,表示状态向量内部变量之间的相关性以及自身的不确定性。设当前时刻为 $k-1$,那么下一时刻的状态向量可以用矩阵形式表示如下:
\[ \begin{align} \color{deeppink}{\boldsymbol{\hat{x}}_k} &= \begin{bmatrix} 1 & \Delta t \\ 0 & 1 \end{bmatrix} \color{royalblue}{\boldsymbol{\hat{x}}_{k-1}} \\ &= \mathbf{F}_k \color{royalblue}{\boldsymbol{\hat{x}}_{k-1}} \end{align} \]
$\mathbf{F}_k$ 称为状态转移矩阵(state transition matrix),也即是预测矩阵。通过该矩阵可以得到下个时刻的状态。那么状态向量的协方差呢?也通过该矩阵传递到下一状态。首先易知有如下关系:
\[ \begin{split} Cov(\boldsymbol{x}) &= \mathbf{\Sigma} \\ Cov(\mathbf{A} \boldsymbol{x}) &= \mathbf{A} \mathbf{\Sigma} \mathbf{A}^T \end{split} \]
那么可得状态向量及其协方差矩阵更新如下:
\[ \begin{split} \color{deeppink}{\boldsymbol{\hat{x}}_k} &= \mathbf{F}_k \color{royalblue}{\boldsymbol{\hat{x}}_{k-1}} \\ \color{deeppink}{\mathbf{P}_k} &= \mathbf{F_k} \color{royalblue}{\mathbf{P}_{k-1}} \mathbf{F}_k^T \end{split} \]
虽然该方程可以预测出物体下个时刻的状态,但它并不完全。可能还有与状态向量无关的因素带来的影响。例如,汽车运动过程中对刹车或油门的控制。假设小车运动时的加速度为 $a$ ,那么我们的运动方程就变为:
\[ \begin{split} p_k & = p_{k-1} + \Delta t & v_{k-1} + \frac{1}{2} a {\Delta t}^2 \\ v_k & = & v_{k-1} + a \Delta t \end{split} \]
表示为矩阵形式:
\[ \begin{split} \color{deeppink} {\boldsymbol{\hat{x}}_k} & = \mathbf{F}_k \color{royalblue} {\boldsymbol {\hat{x}}_{k-1}} + \begin{bmatrix} \frac{{\Delta t}^2}{2} \\ \Delta t \end{bmatrix} a \\ & = \mathbf{F}_{k} \color{royalblue} {\boldsymbol {\hat{x}}_{k-1}} + \mathbf{B}_k \color{darkorange}{\boldsymbol{u}_k} \end{split} \]
$\mathbf{B}_k$ 为控制矩阵(control matrix),$\mathbf{u}_k$ 为控制向量。
到目前为止,若我们考虑了所有对运动状态有影响的因素,便可以根据上述式子对物体的运动状态进行递推。但实际上,还有一些外部的影响是我们没法控制的,比如四轴飞行器被风吹的摇晃,小车轮子打滑等。这些也都会对运动状态产生影响。在卡尔曼滤波中,我们假设这些不确定的因素为服从高斯分布的噪声,其协方差矩阵表示为$\mathbf{Q}_{k}$ 。如此一来,我们的递推关系式变为了:
\[ \begin{split} \color{deeppink}{\boldsymbol{\hat{x}}_k} &= \mathbf{F}_k \color{royalblue}{\boldsymbol{\hat{x}}_{k-1}} + \mathbf{B}_k \color{darkorange}{\boldsymbol{u}_k} \\ \color{deeppink}{\mathbf{P}_k} &= \mathbf{F_k} \color{royalblue}{\mathbf{P}_{k-1}} \mathbf{F}_k^T + \color{mediumaquamarine} {\mathbf{Q}_k} \end{split} \]
状态 新的最优估计 是在 前一个最优估计 的基础预测出来的,再加上一个 已知的外部影响 的修正量。而新的不确定性 则是由 旧的不确定性 预测而来,再加上额外的来自 环境的不确定性。
现在我们利用当前状态预测出了由 $\color{deeppink} {\boldsymbol{\hat{ x}}_k}$ 和 $\color{deeppink} {\mathbf{P}_k}$ 所描述的系统下一时刻的状态,那么当我们有了来自传感器的实际观测值后,应当如何对系统进行更新呢?这里涉及到卡尔曼滤波的关键部分了,也就是将预测的状态与观测的状态进行融合。
利用测量更新预测
传感器得到的测量值可能与状态向量的单位以及标度不同,因此需要将状态向量转换为我们读取的测量值,转换矩阵为 $\mathbf{H}_k$ 。 那么传感器的读数表示如下:
\[ \begin{split} \boldsymbol{\mu}_{expected} &= \mathbf{H}_k \color{deeppink}{\hat{\boldsymbol{x}}_k} \\ \mathbf{\Sigma}_{expected} &= \mathbf{H}_k \color{deeppink}{\mathbf{P}_k} \mathbf{H}_k^T \end{split} \]
卡尔曼滤波海考虑了传感器的噪声影响,也就是说测量值也存在着不确定性,将传感器噪声的协方差表示为 $\color{mediumaquamarine}{\mathbf{R}_k}$ 。那么测量读数表示为 $\color{yellowgreen}{\boldsymbol{\mathbf{z}_k}}$ 。
现在我们有了两个值:一个预测值和一个观测值。两个值都遵循高斯分布。问题变为了如何将两个值融合起来得到新的状态向量。
高斯分布的融合
首先考虑一维的高斯分布:
\[ \mathcal{N}(x, \mu, \sigma) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} \]
现在有两个分布均为高斯分布,将这两个概率密度函数相乘得到一个新的概率密度函数,可以证明这个PDF仍然是高斯分布,推导可得新分布的均值和方差(见附录):
\[ \begin{split} \color{royalblue}{\mu_{fused}} &= \mu_1 + \frac{\sigma_1^2(\mu_2 - \mu_1) }{\sigma_1^2 + \sigma_2^2} \\ \color{royalblue}{\sigma_{fused}^2} &= \sigma_1^2 - \frac{\sigma_1^4}{\sigma_1^2 + \sigma_2^2} \end{split} \]
我们引入$\color{purple}{k}$,那么融合后的高斯分布均值和方差表示为:
\[ \begin{split} \color{royalblue}{\mu_{fused}} & = \mu_1 + k (\mu_2 - \mu_1) \\ \color{royalblue}{\sigma_{fused}^2} &= \sigma_1^2 - k \sigma_1^2 \end{split} \]
其中,$ \color{purple}{k} = \frac{\sigma_12}{\sigma_12 + \sigma_2^2}$
上面是两个一维高斯分布的融合,对于多变量的高斯分布,只需要将方差替换为协方差矩阵,均值替换为均值向量即可:
\[ \begin{split} \color{purple}{\mathbf{K}} &= \Sigma_1(\Sigma_1 + \Sigma_2)^{-1} \\ & \\ \color{royalblue}{\vec{\mu}_{fused}} &= \vec{\mu}_1 + \color{purple}{\mathbf{K}}(\vec{\mu}_2 - \vec{\mu}_1) \\ \color{royalblue}{\Sigma_{fused}} &= \Sigma_1 - \color{purple}{\mathbf{K}} \Sigma_1 \end{split} \]
这里的 $\color{purple}{\mathbf{K}}$ 即为卡尔曼增益系数(Kalman gain) ,也即是将预测值和观测值进行融合的权系数。卡尔曼滤波的贡献就是找到了这个权系数。到此,我们将前面所有的步骤综合起来便是传统的卡尔曼滤波的过程了。
小结
通过状态方程我们得到了预测的状态分布:$(\color{deeppink}{ \mu_1, \mathbf{\Sigma}_1}) = (\color{deeppink}{\mathbf{H}_k \hat{\boldsymbol{x}}_k, \mathbf{H}_k \mathbf{P}_k \mathbf{H}^T})$;然后通过量测方程得到了测量状态分布:$(\color{yellowgreen}{\mu_2}, \color{mediumaquamarine}{\mathbf{\Sigma}_2}) = (\color{yellowgreen}{\boldsymbol{{z}_k}}, \color{mediumaquamarine}{\mathbf{R}_k})$。将两个状态分布代入上式中:
\[ \begin{split} \mathbf{H}_k \color{royalblue}{\hat{ \boldsymbol{x}}_k^{fused}} &= \color{deeppink}{\mathbf{H}_k \hat{\boldsymbol{x}}_k} & + & \color{purple}{\mathbf{K}} (\color{yellowgreen}{\vec{\mathbf{z}_k}} - \color{deeppink}{\mathbf{H}_k \hat{\boldsymbol{x}}_k}) \\ \mathbf{H}_k \color{royalblue}{\mathbf{P}_k^{fused}} \mathbf{H}_k^T &= \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} & – & \color{purple}{\mathbf{K}} \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} \end{split} \]
同时可以得到卡尔曼增益为:
\[ \begin{equation} \label{eq:kalgainunsimplified} \color{purple}{\mathbf{K}} = \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} ( \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} + \color{mediumaquamarine}{\mathbf{R}_k})^{-1} \end{equation} \]
从上面三个式子中都消掉一个 $\mathbf{H}_k$ 可得:
\[ \begin{equation} \begin{split} \color{royalblue}{\boldsymbol{\hat{x}}_k^{fused}} &= \color{fuchsia}{\boldsymbol{\hat{x}}_k} & + & \color{purple}{\mathbf{K}’} ( \color{yellowgreen}{{\boldsymbol{z}_k}} – \color{fuchsia}{\mathbf{H}_k \boldsymbol{\hat{x}}_k} ) \\ \color{royalblue}{\mathbf{P}_k^{fused}} &= \color{deeppink}{\mathbf{P}_k} & – & \color{purple}{\mathbf{K}’} \color{deeppink}{\mathbf{H}_k \mathbf{P}_k} \end{split} \label{kalupdatefull} \end{equation} \]
其中:
\[ \begin{equation} \color{purple}{\mathbf{K}’} = \color{deeppink}{\mathbf{P}_k \mathbf{H}_k^T} ( \color{deeppink}{\mathbf{H}_k \mathbf{P}_k \mathbf{H}_k^T} + \color{mediumaquamarine}{\mathbf{R}_k})^{-1} \label{kalgainfull} \end{equation} \]
这样,一个完整的迭代更新流程就完成了。$\color{royalblue}{\boldsymbol{\hat{x}}_k^{fused}}$ 为新的最优估计,可以在此基础上继续预测-更新的递推下去。
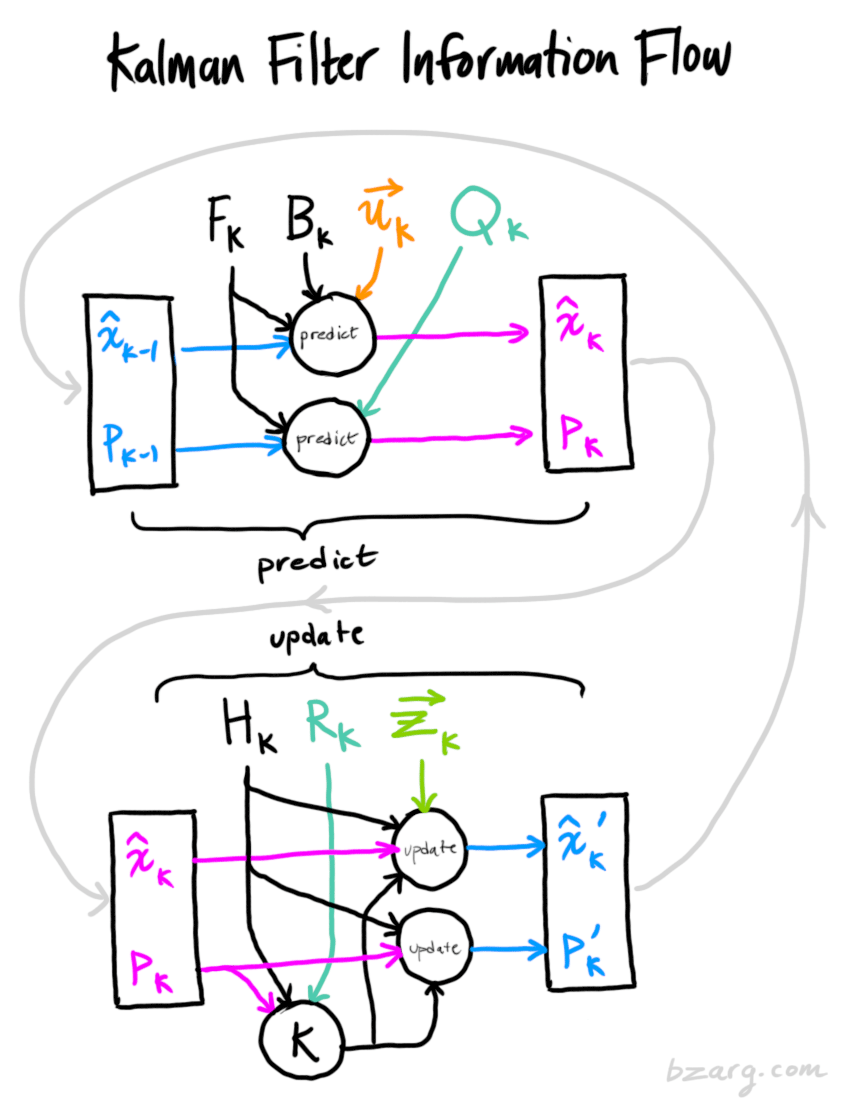
总结
卡尔曼滤波的核心思想在于信息融合(information fusion):如何将预测和观测两个量融合得到新的描述物体运动的状态量。
卡尔曼滤波可以对线性系统进行准确的预测。对于非线性系统,则需要利用扩展卡尔曼滤波(Extended Kalman filter),通过将问题线性化来进行。
附录
协方差
\[ \begin{split} Cov(x) &= \Sigma \\ Cov(\mathbf{A}x) &= \mathbf{A} \Sigma \mathbf{A}^T \end{split} \]
已知:
\[ Cov(\boldsymbol{x}) = \boldsymbol{x} \boldsymbol{x}^T \]
那么
\[ \begin{split} Cov(\mathbf{A} \boldsymbol{x}) &= \mathbf{A} \boldsymbol{x} (\mathbf{A} \boldsymbol{x})^T \\ &= \mathbf{A} \boldsymbol{x} \boldsymbol{x}^T \mathbf{A}^T \\ &= \mathbf{A} \mathbf{\Sigma} \mathbf{A}^T \end{split} \]
高斯分布的乘积仍为高斯分布
设有高斯分布 $p_1(x) = \mathcal{N}(\mu_1, \sigma_1)$ 和 $p_2(x) = \mathcal{N}(\mu_2, \sigma_2)$ , 那么其乘积为:
\[ \begin{split} p_{fused} &= \frac{1}{\sigma_1 \sqrt{2\pi}} e^{-\frac{(x-\mu_1)^2}{2\sigma_1^2}} \times \frac{1}{\sigma_2 \sqrt{2\pi}} e^{-\frac{(x-\mu_2)^2}{2\sigma_2^2}} \\ &= \frac{1}{\sigma_1 \sigma_2 2\pi} e^{ - \left[ \frac{(x-\mu_1)^2}{2\sigma_1^2} + \frac{(x-\mu_2)^2}{2\sigma_2^2} \right]} \\ &= \frac{1}{\sigma_{fused} \sqrt{2\pi}} e ^{-\frac{(x-\mu_{fused})^2}{2\sigma_{fused}^2}} \end{split} \]
经化简可得:
\[ \begin{split} \mu_{fused} &= \frac{\mu_1 \sigma_2^2 + \mu_2 \sigma_1^2} {\sigma_1^2 + \sigma_2^2} \\ &= \mu_1 + \frac{\sigma_1^2(\mu_2 - \mu_1)}{\sigma_1^2 + \sigma_2^2} \end{split} \]
\[ \sigma_{fused}^2 = \frac{\sigma_1^2 \sigma_2^2}{\sigma_1^2 + \sigma_2^2} \]